




hadoop 2.9.2 完全分布式搭建 [ 哔哔大数据 ]
大数据男孩 文章 正文
明妃
{{nature("2022-08-14 17:23:14")}}更新相关配置版本
| 组件 | 版本 | 提取码 |
|---|---|---|
| Hadoop | 2.9.2 | qtf9 |
| jdk | 1.8.0_221 | yjwt |
| centOS | 7.0 | bodr |
环境准备
1. 修改机器名称
机器名称映射
master: 192.168.5.139
slave1: 192.168.5.143
slave2: 192.168.5.145
修改机器名文件:vi /etc/hostname
执行:hostname 机器名
检查:hostname2. 修改master的 hostname 与 ip 的映射
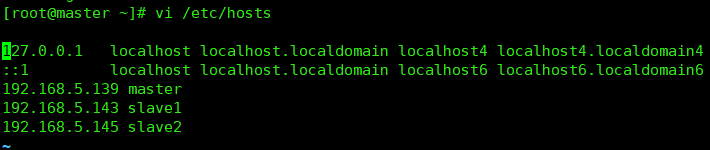
修改的文件:vi /etc/hosts
192.168.5.139 master
192.168.5.143 slave1
192.168.5.145 slave2
master 修改完成,把 hosts 发送到slave1、slave1节点
for i in {1..2};do scp /etc/hosts root@slave${i}:/etc;done[]()
- 角色分配
| 机器名称 | 节点 | 节点 |
|---|---|---|
| master | DataNode / NameNode | NodeManager / ResourceManager |
| slave1 | DataNode | NodeManager |
| slave2 | DataNode | NodeManager |
前置配置
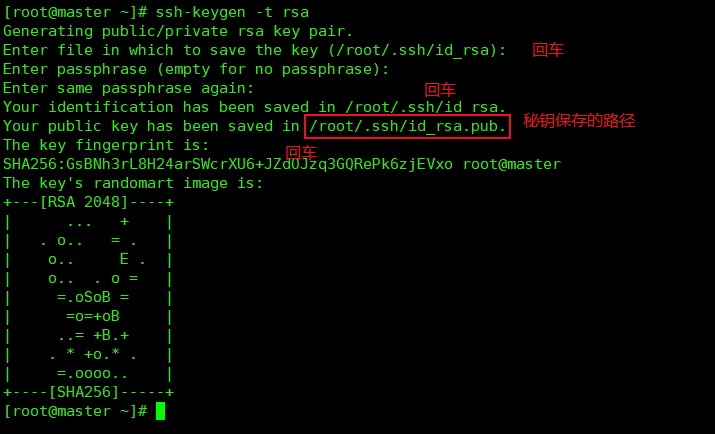
1. ssh免密码登录
每台机器执行:
ssh-keygen -t rsa[]()
- 把 master 节点上的
authorized_keys钥发送到其他节点
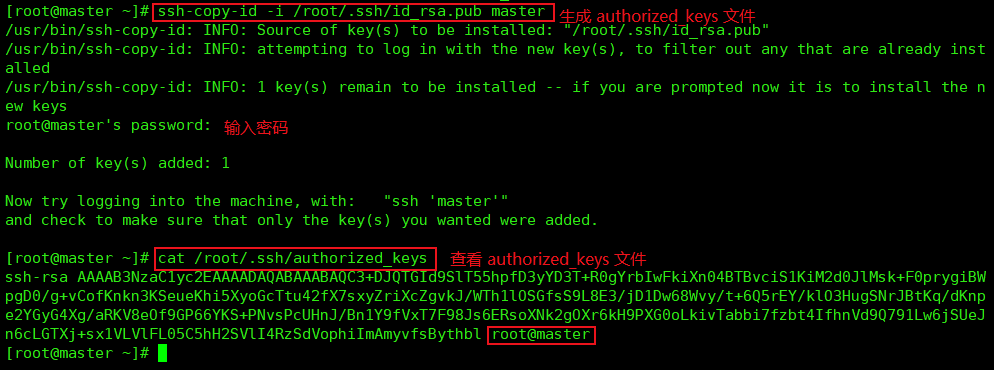
master 执行命令,生成 authorized_keys 文件:
ssh-copy-id -i /root/.ssh/id_rsa.pub master
把 authorized_keys 发送到 slave1 slave2 节点上
scp /root/.ssh/authorized_keys root@slave1:/root/.ssh/
scp /root/.ssh/authorized_keys root@slave2:/root/.ssh/
[]()
[]()
- 在 master 节点测试免密码登录 slave1、slave2
命令:ssh 机器名[]()
2. 配置 master 的 jdk,后面与 hadoop 一起发送到 其他节点
Hadoop 集群的搭建
解压Hadoop安装包,配置环境变量
- 解压hadoop安装包到
/usr/local/src/hadoop目录下,并配置HADOOP_HOME到环境变量
[]()
[]()
修改配置文件
进入 hadoop 的hadoop-2.9.2/etc/hadoop目录下
1. 修改 hadoop-env.sh 文件
第一处
# The java implementation to use.
# export JAVA_HOME=${JAVA_HOME} (注释掉)
export JAVA_HOME=/usr/local/src/jdk1.8.0_221 (添加上)
第二处
# export HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-"/etc/hadoop"} (注释)
export HADOOP_CONF_DIR=/usr/local/src/hadoop-2.9.2/etc/hadoop (添加上)
修改完记得 source hadoop-env.sh2. 修改 core-site.xml 文件
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<!--临时目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/src/hadoop-2.9.2/tmp</value>
</property>
</configuration>3. 修改 hdfs-site.xml 文件
- 添加到 hdfs-site.xml 文件
<configuration>
<!--block 块的复制数量-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- namenode 的 http协议 地址和端口-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
<!-- namenode 的 https协议 地址和端口-->
<property>
<name>dfs.namenode.secondary.https-address</name>
<value>master:50091</value>
</property>
</configuration>4. 修改 yarn-site.xml 文件
<configuration>
<!-- 用于存储本地化文件的目录列表 -->
<!-- 创建目录 mkdir -p /usr/local/src/nm/localdir -->
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/usr/local/src/nm/localdir</value>
</property>
<!-- reducer 获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定 yarn 的 resourcemanager 的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
</property>
<!-- 忽略虚拟内存的检查 虚拟机上设置有很大用处 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
<description>Whether virtual memory limits will be enforced for containers</description>
</property>
<!-- yarn 分配的内存大小 -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>3276</value>
</property>
<!-- 每台机器最大分配内存,超过 报异常 -->
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>3276</value>
</property>
<!-- yarn 分配的 CPU 个数 -->
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>4</value>
</property>
<!-- 每台机器最大分配CPU个数,超过 报异常 -->
<property>
<name>yarn.scheduler.maximum-allocation-vcores</name>
<value>4</value>
</property>
</configuration>5. 修改 mapred-site.xml 文件
- 首先拷贝一份:
cp mapred-site.xml.template mapred-site.xml
<configuration>
<!-- mapreduce 运行时的框架,可以是 local, classic or yarn -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- mapreduce 历史任务的地址端口 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<!-- MapReduce JobHistory 服务器 Web UI 主机:端口 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>6. 修改 slaves 文件
- 这个文件就是规定
从节点运行的机器
删除原本的 localhost
添加上
master
slave1
slave2分发配置文件到 slave1,slave2
把 hadoop 、 java 分发到 slave1 、 slave2
scp -r /usr/local/src/ root@slave1:/usr/local/
scp -r /usr/local/src/ root@slave2:/usr/local/[]()
把 环境变量 文件分发到 slave1、slave2
scp /etc/profile root@slave1:/etc/
scp /etc/profile root@slave2:/etc/
分发完记得去 slave1、slave2 source /etc/profile启动 Hadoop 集群
1.格式化 namenode 节点
只需要在 master 机器上执行就好 hdfs namenode -format
2. 启动集群:在master上执行 start-all.sh
验证
jps 验证
| master | slave1 | slave2 |
|---|---|---|
| Jps | Jps | Jps |
| NodeManager | NodeManager | NodeManager |
| DataNode | DataNode | DataNode |
| NameNode | ||
| SecondaryNameNode | ||
| ResourceManager |
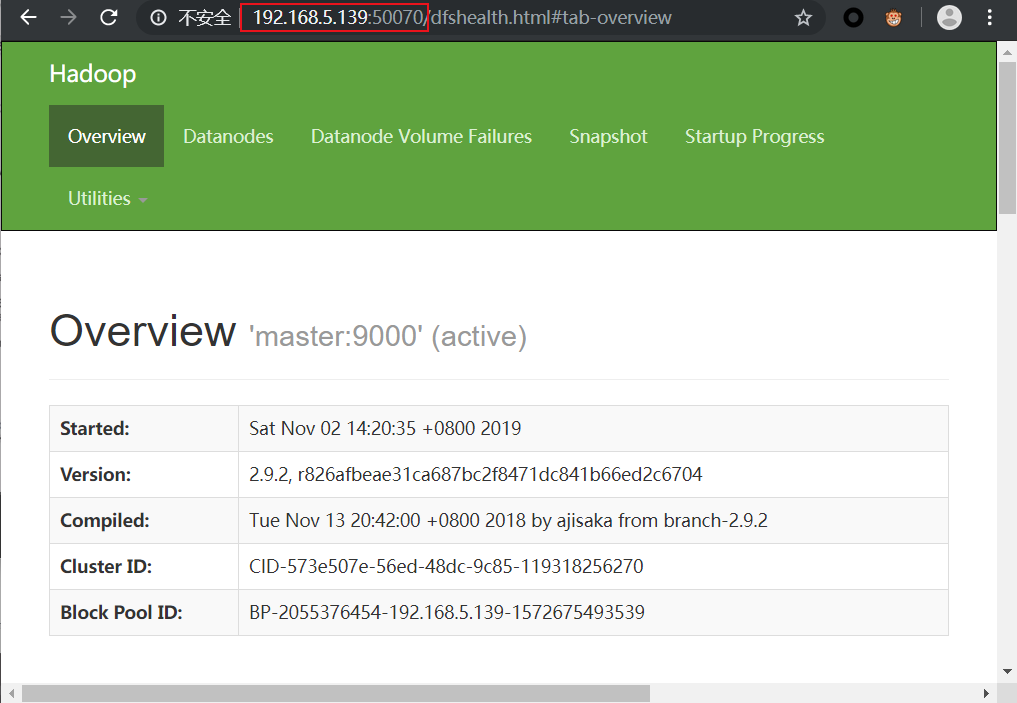
网页端验证
- 关闭防火墙
systemctl stop firewalld.service
master机器IP:50070
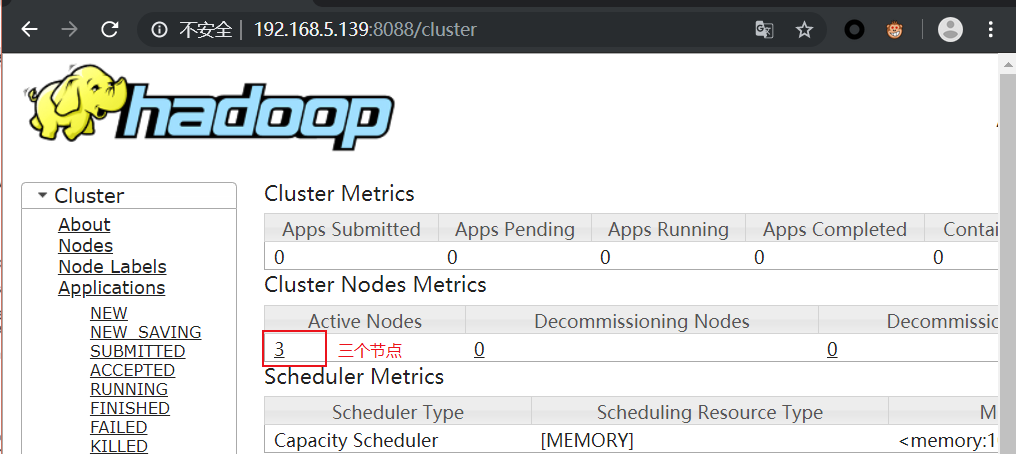
master机器IP:8088[]()
[]()
{{nature('2020-01-02 16:47:07')}} {{format('12518')}}人已阅读
{{nature('2019-12-11 20:43:10')}} {{format('9407')}}人已阅读
{{nature('2019-12-26 17:20:52')}} {{format('7400')}}人已阅读
{{nature('2019-12-26 16:03:55')}} {{format('4877')}}人已阅读
目录
标签云
一言
评论 0
{{userInfo.data?.nickname}}
{{userInfo.data?.email}}