Spark 2.0 单机模式与集群模式 安装 [ 哔哔大数据 ]
大数据男孩 文章 正文
明妃
{{nature("2022-08-14 17:23:15")}}更新单机安装
Spark 的单机安装是很简单的
解压安装包
[root@master spark]# tar -zxvf spark-2.0.0-bin-hadoop2.6.tgz
[root@master spark]# ll
总用量 0
drwxr-xr-x. 12 500 500 193 7月 20 2016 spark-2.0.0-bin-hadoop2.6
[root@master spark]# pwd
/usr/local/src/spark配置环境变量
[root@master spark]# vi ~/.bash_profile
# 加入环境变量
# Spark
export SPARK_HOME=/usr/local/src/spark/spark-2.0.0-bin-hadoop2.6
export PATH=$PATH:$SPARK_HOME/bin:
[root@master spark]# source ~/.bash_profile安装测试
Spark 的 shell 命令
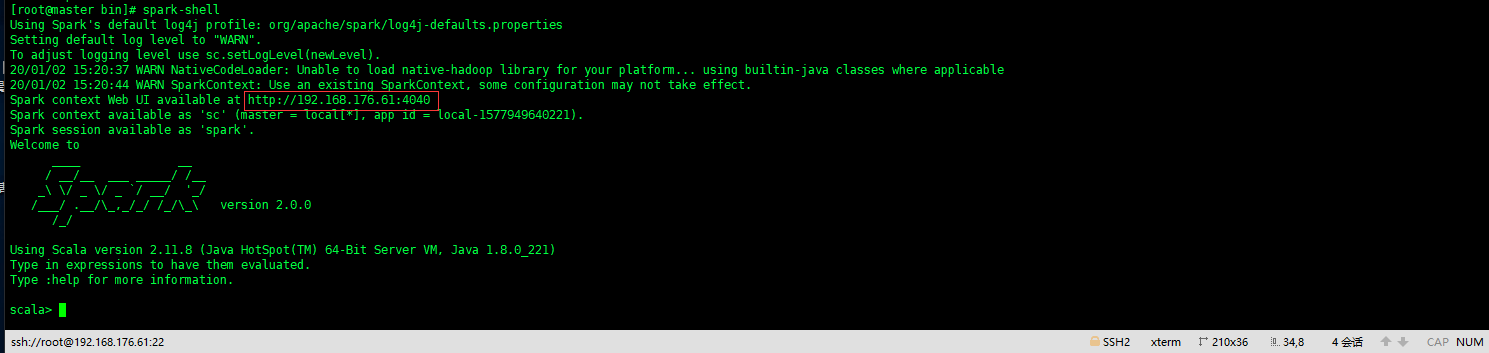
[root@master spark]# spark-shell
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel).
20/01/02 15:29:53 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
20/01/02 15:29:55 WARN Utils: Service 'SparkUI' could not bind on port 4040. Attempting port 4041.
20/01/02 15:29:55 WARN SparkContext: Use an existing SparkContext, some configuration may not take effect.
Spark context Web UI available at http://192.168.176.61:4041
Spark context available as 'sc' (master = local[*], app id = local-1577950195083).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.0.0
/_/
Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_221)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
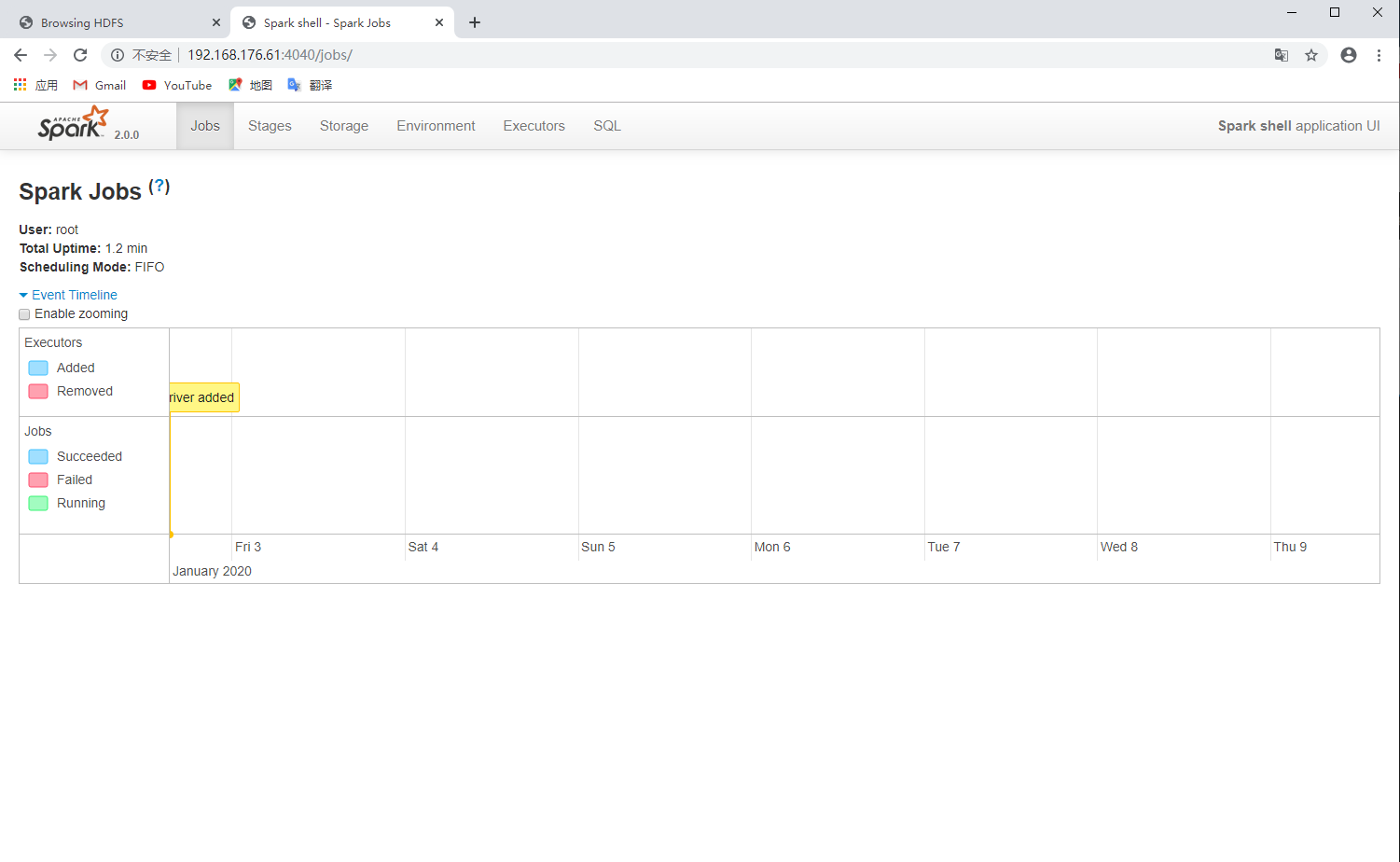
启动后的控制台界面和web界面,这样就算安装成功
[]()
[]()
Spark 的集群安装
在单机模式的安装上,再进行相应的配置
修改 slaves
进入 Spakr的 conf/目录下,复制一个 slaves模板
# 复制 slaves模板
[root@master conf]# cp slaves.template slaves
# 打开 slaves
[root@master conf]# vi slaves
# 加入节点机器的映射名称,映射在配置 Hadoop集群的时候已经配置
master
slave1
slave2修改 spark-env.sh
export JAVA_HOME=/usr/lib/jvm/jdk8u191-b12
export SCALA_HOME=/home/modules/spark-2.3.0/examples/src/main/scala
export HADOOP_HOME=/home/modules/hadoop-2.8.3
export HADOOP_CONF_DIR=/home/modules/hadoop-2.8.3/etc/hadoop
export SPARK_HOME=/home/modules/spark-2.3.0
export SPARK_DIST_CLASSPATH=$(/home/modules/hadoop-2.8.3/bin/hadoop classpath)
export LD_LIBRARY_PATH=/home/modules/hadoop-2.8.3/lib/native
export YARN_CONF_DIR=/home/modules/hadoop-2.8.3/etc/hadoop
export SPARK_MASTER_IP=node1分发配置到其他机器上
分发Spark
scp -r spark/ root@slave1:/usr/local/src/
scp -r spark/ root@slave2:/usr/local/src/分发环境变量
scp ~/.bash_profile root@slave1:~/.bash_profile
scp ~/.bash_profile root@slave1:~/.bash_profile启动Spark集群
进入 Spark的 sbin/目录下执行启动命令
[root@master sbin]# start-all.sh
org.apache.spark.deploy.master.Master running as process 14018. Stop it first.
master: org.apache.spark.deploy.worker.Worker running as process 14365. Stop it first.
slave1: org.apache.spark.deploy.worker.Worker running as process 1952. Stop it first.
slave2: org.apache.spark.deploy.worker.Worker running as process 2616. Stop it first.启动测试
个机器出现以下就是搭建成功
| master | slave1 | slave2 |
|---|---|---|
| NodeManager | NodeManager | NodeManager |
| Jps | Jps | Jps |
| DataNode | DataNode | DataNode |
| Worker | Worker | Worker |
| NameNode | ||
| Master | ||
| SecondaryNameNode | ||
| ResourceManager | ||
| SparkSubmit | ||
| SparkSubmit | ||
| SparkSubmit |
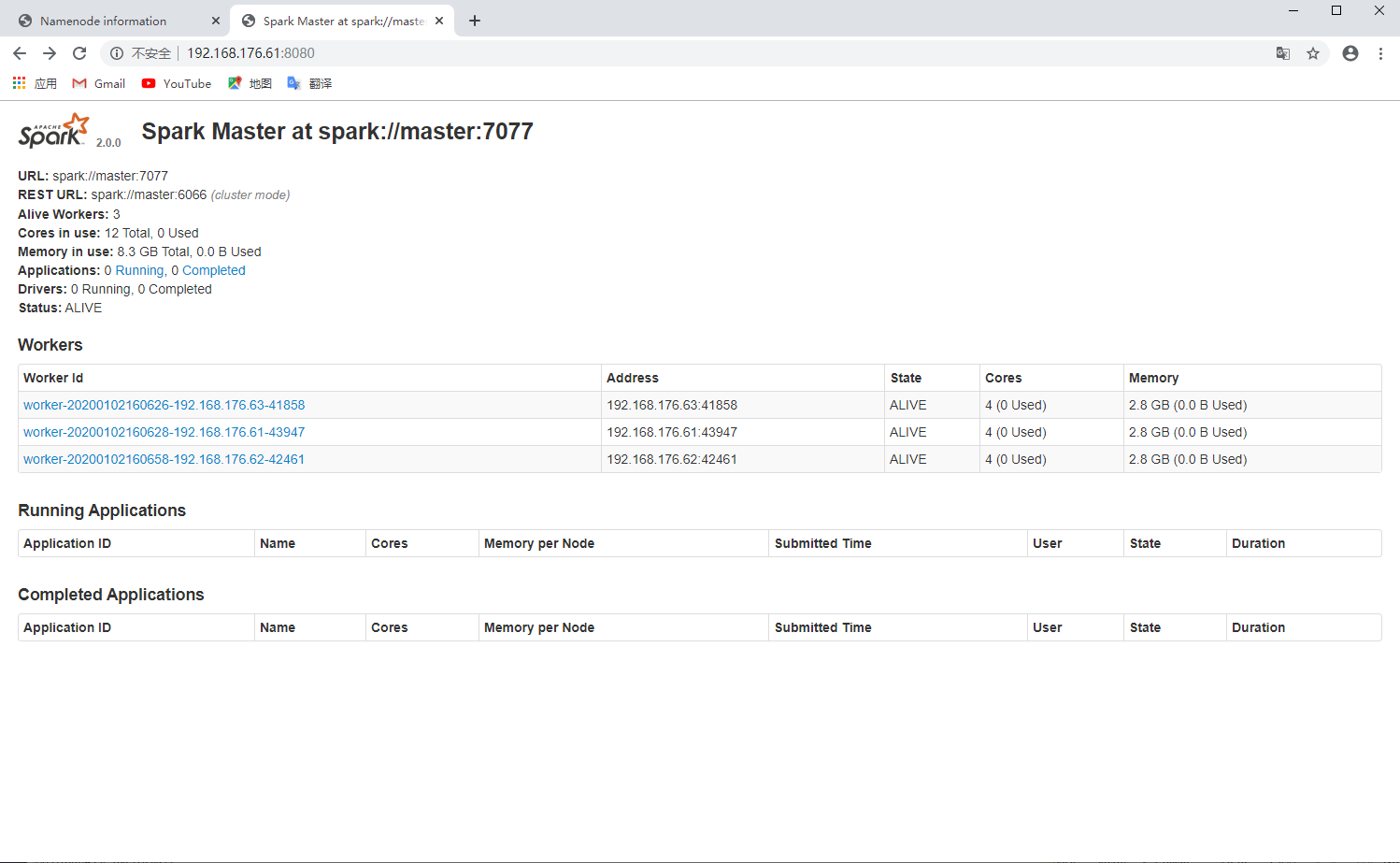
进入 Master:8080 查看集群模式网页
[]()
{{nature('2020-01-02 16:47:07')}} {{format('12580')}}人已阅读
{{nature('2019-12-11 20:43:10')}} {{format('9459')}}人已阅读
{{nature('2019-12-26 17:20:52')}} {{format('7459')}}人已阅读
{{nature('2019-12-26 16:03:55')}} {{format('4942')}}人已阅读
目录
标签云
一言
评论 0
{{userInfo.data?.nickname}}
{{userInfo.data?.email}}