hadoop 常见错误(遇到补充) [ 哔哔大数据 ]
大数据男孩 文章 正文
明妃
{{nature("2022-08-14 17:23:14")}}更新name 文件夹不存在
- 错误描述:
Directory /usr/local/src/hadoop/tmp/dfs/name is in an inconsistent state: storage directory does not exist or is not accessible. - 处理方法:创建name文件 重新格式化 再次启动
[]()
namenode 无法启动
- 错误描述:当把 hadoop 停止之后,再次启动 没有
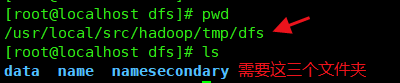
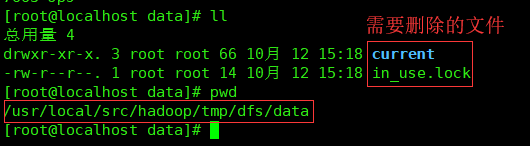
namenode节点 - 处理方法:清空临时目录
tmp里面的data下的东西,再次启动 []()
namenode 处于安全模式
- 错误描述
Name node is in safe mode.Name node处于安全模式 - 处理方式:
- 关闭安全模式
hadoop dfsadmin -safemode leave - 进入安全模式
hadoop dfsadmin -safemode enter
- 关闭安全模式
Hive 无法跑MR任务
- 错误描述
Task with the most failures(4):
-----
Task ID:
task_1594519690907_0001_m_000000
URL:
http://0.0.0.0:8088/taskdetails.jsp?jobid=job_1594519690907_0001&tipid=task_1594519690907_0001_m_000000
-----
Diagnostic Messages for this Task:
Container launch failed for container_1594519690907_0002_01_000005 : org.apache.hadoop.yarn.exceptions.InvalidAuxServiceException: The auxService:mapreduce_shuffle does not exist
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at org.apache.hadoop.yarn.api.records.impl.pb.SerializedExceptionPBImpl.instantiateExceptionImpl(SerializedExceptionPBImpl.java:171)
at org.apache.hadoop.yarn.api.records.impl.pb.SerializedExceptionPBImpl.instantiateException(SerializedExceptionPBImpl.java:182)
at org.apache.hadoop.yarn.api.records.impl.pb.SerializedExceptionPBImpl.deSerialize(SerializedExceptionPBImpl.java:106)
at org.apache.hadoop.mapreduce.v2.app.launcher.ContainerLauncherImpl$Container.launch(ContainerLauncherImpl.java:162)
at org.apache.hadoop.mapreduce.v2.app.launcher.ContainerLauncherImpl$EventProcessor.run(ContainerLauncherImpl.java:393)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 HDFS Read: 0 HDFS Write: 0 FAIL
Total MapReduce CPU Time Spent: 0 msec- 处理方式:
# 确认 yarn-site.xml 的配置是否正确
<!--NodeManager获取数据的方式-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
# 然后重启 Hadoop{{nature('2020-01-02 16:47:07')}} {{format('12641')}}人已阅读
{{nature('2019-12-11 20:43:10')}} {{format('9527')}}人已阅读
{{nature('2019-12-26 17:20:52')}} {{format('7573')}}人已阅读
{{nature('2019-12-26 16:03:55')}} {{format('5017')}}人已阅读
目录
标签云
一言
评论 0
{{userInfo.data?.nickname}}
{{userInfo.data?.email}}