原生Js 实现 innerHTML 方法(借鉴 Js 解释器 思想 ) [ 编程杂谈 ]
大数据男孩 文章 正文
明妃
{{nature("2022-08-14 17:23:19")}}更新注:有好久没更新了,也不是说没有学习,主要Js逆向,不适合发在网站上
本文借鉴自:https://juejin.cn/post/6844903811601924103
在此篇文章上进行了一点优化:处理标签多个属性值,增加属性值的兼容性
说明
Js innerHTML 方法是把 文本型的 HTML 标签 转换成 DOM 树,实现过程与 解释器 差不多,也算了解一下解释器
解释器步骤
词法分析 -> 语法分析 -> 解释执行词法分析
词法分析的具体任务就是:把字符流变成 token流。
词法分析通常有两种方案:一种是状态机,一种是正则表达式。我们这里选择状态机。
状态机的原理
将整个 HTML 字符串进行遍历,每次读取一个字符,进行一次决策(决定出下一个字符处于哪个状态),当一个状态决策完成的token 就会被存入到 tokens 里。
<p class="yy" id="xx">测试元素</p>对于上述节点信息,我们可以拆分出如下 token
- 开始标签:
<p - 属性标签:
class="yy" - 属性标签:
id="xx" - 文本节点:
测试元素 - 结束标签:
</p>
词法分析函数说明
封装开头函数
function HTMLLexicalParser(htmlString, tokenHandler) {
this.token = [];
// 存储已经分析完成的 一个个 token
this.tokens = [];
// 标签属性词法分析结束标志 为处理标签多个属性添加
this.attrFlag = 0;
// 待处理的字符串
this.htmlString = htmlString
// 处理函数 tokens 转换成 树结构函数
this.tokenHandler = tokenHandler
}start 函数
start处理的比较简单,如果是<字符,表示开始标签或结束标签,因此我们需要下一个字符信息才能确定到底是哪一类 token,所以返回 tagState 函数去进行再判断,否则认为是文本节点,返回文本状态函数
HTMLLexicalParser.prototype.start = function(c) {
if (c === '<') {
// 表示开始标签或结束标签,所以 需要进一步确认
this.token.push(c) // 记录 token
return this.tagState
} else {
return this.textState(c)
}
}tagState 、textState 函数
tagState根据下一个字符,判断进入开始标签状态还是结束标签状态,如果是/表示是结束标签,否则是开始标签
textState用来处理每一个文本节点字符,遇到<表示得到一个完整的文本节点 token。
HTMLLexicalParser.prototype.tagState = function(c) {
this.token.push(c)
if (c === '/') {
// 表示结束状态,返回结束处理函数
return this.endTagState
} else {
// 表示开始处理标签状态,接下来会有 字母(开始)、空格(属性)、>(标签结束)
return this.startTagState
}
}
HTMLLexicalParser.prototype.textState = function(c) {
if (c === '<') {
// 表示文本状态处理完成,把 此窗台存入 tokens 中
this.emitToken('text', this.token.join(''));
this.token = [] // 置空 token 准备处理下一状态
return this.start(c)
} else {
// 还处理文本状态
this.token.push(c)
return this.textState
}
}emitToken、startTagState、endTagState 函数
emitToken 用来将产生的完整 token 存储在 tokens 中,参数是 token 类型和值。
startTagState 用来处理开始标签,这里有三种情况:
- 接下来的
字符是字母,则认定依旧处于开始标签状态 - 遇到
空格,则认定 开始标签态结束,接下来是处理属性 - 遇到
>同样认定为 开始标签态结束,但接下来是处理新的 节点信息
endTagState 用来处理结束标签,结束标签没有属性,因此只有两种情况:
- 如果接下来的
字符是字母,则认定依旧处于结束标签态 - 遇到
>同样认定为结束标签态结束,但接下来是处理新的 节点信息
HTMLLexicalParser.prototype.emitToken = function(type, value) {
var res = {
type,
value
}
this.tokens.push(res)
// 流式处理
this.tokenHandler && this.tokenHandler(res)// 存在则执行该函数
}
HTMLLexicalParser.prototype.startTagState = function(c) {
if (c.match(/[a-zA-Z]/)) {
// 处理标签名状态
this.token.push(c.toLowerCase())
return this.startTagState
}
if (c === ' ') {
// 标签名状态结束 进入标签属性状态
this.emitToken('startTag', this.token.join(''))
this.token = []
return this.attrState
}
if (c === '>') {
// 标签结束状态 进入开始分析状态
this.emitToken('startTag', this.token.join(''))
this.token = []
return this.start
}
}
HTMLLexicalParser.prototype.endTagState = function(c) {
if (c.match(/[a-zA-Z]/)) {
// 双标签结束时状态
this.token.push(c.toLowerCase())
return this.endTagState
}
if (c === '>') {
// 双标签结束时状态 进入开始分析状态
this.token.push(c)
this.emitToken('endTag', this.token.join(''))
this.token = []
return this.start
}
}attrState
attrState 处理属性标签,也处理三种情形
- 如果是
字母、数字、等号、下划线、空格、中划线、冒号、分号,则认定为依旧处于属性标签态 - 如果遇到
引号,则表示遇到标签属性值,第二次遇到才表示一个标签属性结束(不代表标签状态结束),继续处理 标签状态 - 如果遇到
>则认定为属性标签状态结束,接下来开始新的 节点信息
HTMLLexicalParser.prototype.attrState = function(c) {
if (c.match(/[a-zA-Z0-9=_ \-\:;]/)) {
this.token.push(c)
return this.attrState
}
if (c.match(/['"]/)) {
this.attrFlag = this.attrFlag + 1;
if (this.attrFlag == 2) {
this.token.push(c)
this.emitToken('attr', this.token.join(''))
this.token = []
this.attrFlag = 0;
return this.attrState
}
this.token.push(c)
return this.attrState
}
if (c === '>') {
return this.start
}
}parse、getOutPut
parse 解析函数 getOutPut 输出解析结果函数
HTMLLexicalParser.prototype.parse = function() {
var state = this.start;
for (var c of this.htmlString.split('')) {
state = state.bind(this)(c)
}
}
HTMLLexicalParser.prototype.getOutPut = function() {
return this.tokens
}测试词法分析
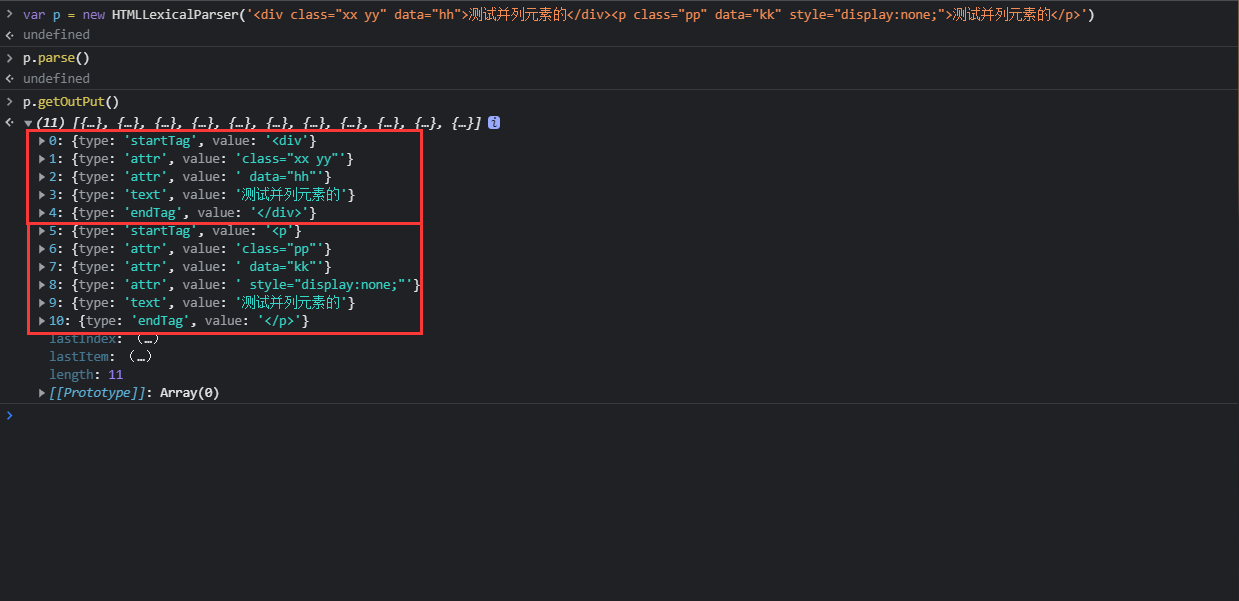
var p = new HTMLLexicalParser('<div class="xx yy" data="hh">测试并列元素的</div><p class="pp" data="kk" style="display:none;">测试并列元素的</p>')
p.parse()
p.getOutPut()[]()
语法分析
语法分析:就是把 上一步 分析的结果,处理成有层次的树结构
定义树结构
// 语法分析
function Element(tagName) {
this.tagName = tagName
this.attr = {}
this.childNodes = []
}
function Text(value) {
this.value = value || ''
}处理词法分析结果思路
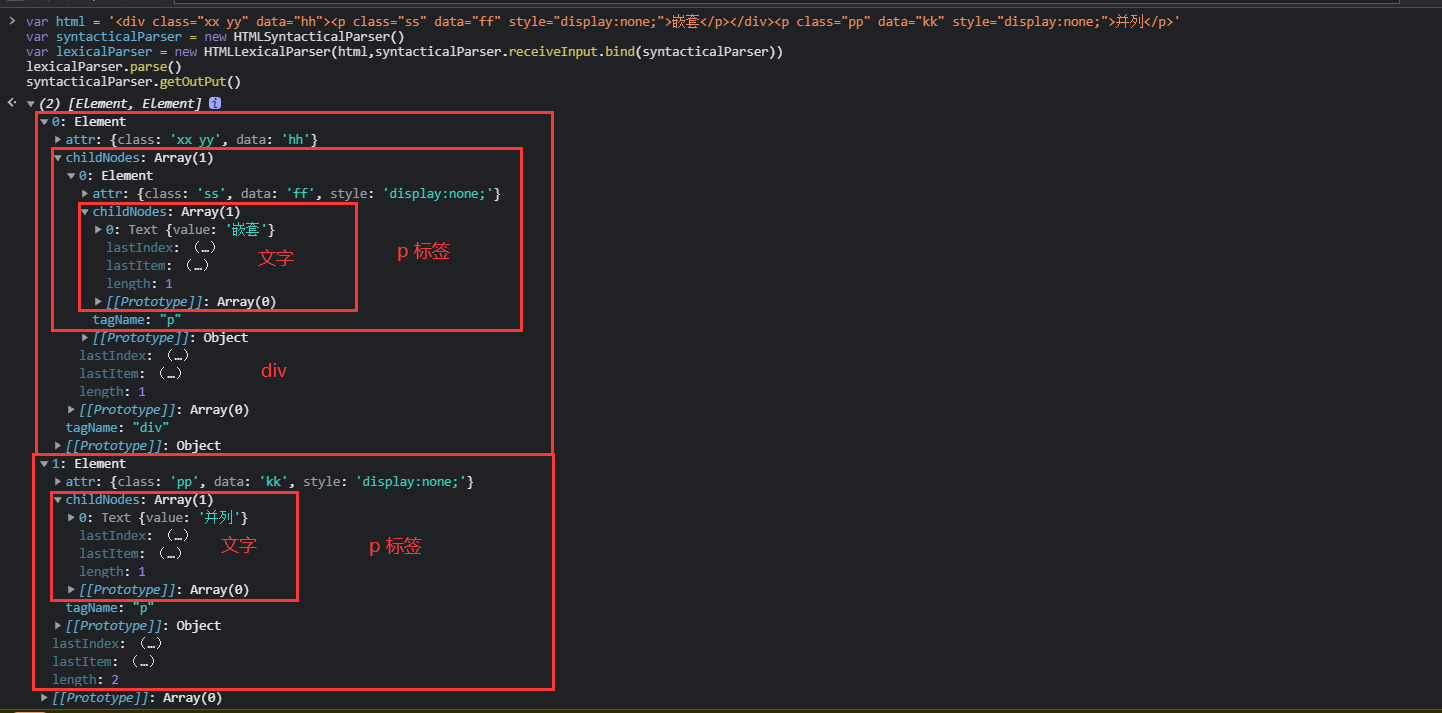
[]()
通过上图分析结果 很容易看出层次结构
- startTag token, push 一个新节点 element
- endTag token,则表示
当前节点处理完成,此时出栈一个节点,同时将该节点归入栈顶元素节点的childNodes属性,这里需要做个判断,如果出栈之后栈空了,表示整个节点处理完成,考虑到可能有平行元素,将元素 push 到 stacks。 - attr token,
直接写入栈顶元素的 attr 属性 - text token,由于文本节点的特殊性,不存在有子节点、属性等,就认定为处理完成。这里需要做个判断,因为文本节点可能是根级别的,判断是否存在栈顶元素,如果存在直接压入栈顶元素的 childNodes 属性,不存在 push 到 stacks。
function HTMLSyntacticalParser() {
this.stack = []
this.stacks = []
}
HTMLSyntacticalParser.prototype.getOutPut = function() {
return this.stacks
}
// 一开始搞复杂了,合理利用基本数据结构真是一件很酷炫的事
HTMLSyntacticalParser.prototype.receiveInput = function(token) {
var stack = this.stack
console.log('token',token)
if (token.type === 'startTag') {
stack.push(new Element(token.value.substring(1)))
} else if (token.type === 'attr') {
var t = token.value.split('=');
//console.log('t',t);
var key = t[0].replace(/^\s*|\s*$/g,""), value = t[1].replace(/'|"/g, '')
stack[stack.length - 1].attr[key] = value
} else if (token.type === 'text') {
if (stack.length) {
stack[stack.length - 1].childNodes.push(new Text(token.value))
} else {
this.stacks.push(new Text(token.value))
}
} else if (token.type === 'endTag') {
var parsedTag = stack.pop()
if (stack.length) {
stack[stack.length - 1].childNodes.push(parsedTag)
} else {
this.stacks.push(parsedTag)
}
}
console.log(stack);
}测试语法分析结果
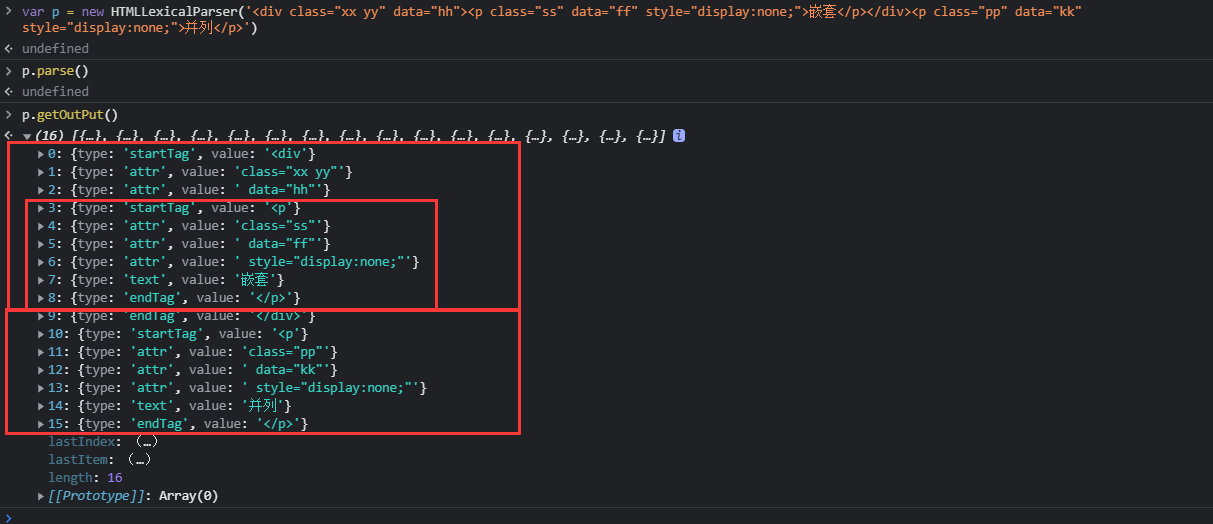
var html = '<div class="xx yy" data="hh"><p class="ss" data="ff" style="display:none;">嵌套</p></div><p class="pp" data="kk" style="display:none;">并列</p>'
var syntacticalParser = new HTMLSyntacticalParser()
var lexicalParser = new HTMLLexicalParser(html,syntacticalParser.receiveInput.bind(syntacticalParser))
lexicalParser.parse()
syntacticalParser.getOutPut()[]()
解释执行
就是把上面的 树结构,使用递归映射成真实的 dom 结构
function vdomToDom(array) {
var res = []
for (let item of array) {
res.push(handleDom(item))
}
return res
}
function handleDom(item) {
if (item instanceof Element) {
var element = document.createElement(item.tagName)
for (let key in item.attr) {
element.setAttribute(key, item.attr[key])
}
if (item.childNodes.length) {
for (let i = 0; i < item.childNodes.length; i++) {
element.appendChild(handleDom(item.childNodes[i]))
}
}
return element
} else if (item instanceof Text) {
return document.createTextNode(item.value)
}
}封装函数
function html(element, htmlString) {
var syntacticalParser = new HTMLSyntacticalParser()
var lexicalParser = new HTMLLexicalParser(htmlString,syntacticalParser.receiveInput.bind(syntacticalParser))
lexicalParser.parse()
var dom = vdomToDom(syntacticalParser.getOutPut())
var fragment = document.createDocumentFragment()
dom.forEach(item=>{
fragment.appendChild(item)
})
element.appendChild(fragment)
}我修改过的代码地址:https://pan.bigdataboy.cn/s/MzmIB
{{nature('2020-01-02 16:47:07')}} {{format('12641')}}人已阅读
{{nature('2019-12-11 20:43:10')}} {{format('9527')}}人已阅读
{{nature('2019-12-26 17:20:52')}} {{format('7573')}}人已阅读
{{nature('2019-12-26 16:03:55')}} {{format('5017')}}人已阅读
目录
标签云
一言
评论 0
{{userInfo.data?.nickname}}
{{userInfo.data?.email}}