ZooKeeper + Hadoop HA( 高可用 )安装 [ 哔哔大数据 ]
大数据男孩 文章 正文
明妃
{{nature("2022-08-14 17:23:15")}}更新安装前说明
版本说明
| 组件 | 版本 | 下载地址 |
|---|---|---|
| Hadoop | 2.6.0 | 点我下载 |
| ZooKeeper | 3.4.5 | 点我下载 |
机器分配
| 机器IP | 机器名 | 分配 |
|---|---|---|
| 192.168.176.61 | master | namenode |
| 192.168.176.62 | slave1 | namenode |
| 192.168.176.63 | slave2 | 其他 |
修改机器名
hostnamectl set-hostname master
hostnamectl set-hostname slave1
hostnamectl set-hostname slave2修改 IP 与机器名的映射
# 修改的文件:vi /etc/hosts
# 追加
192.168.176.61 master
192.168.176.62 slave1
192.168.176.63 slave2配置免密登陆
有 namenode的 机器能免密登陆其他机器
# 每台机器执行:
ssh-keygen -t rsa
# 在准备有 namenode 进程的机器上执行
ssh-copy-id -i /root/.ssh/id_rsa.pub 机器名
# 再把准备有 namenode 进程机器上的密钥发送给其他机器
# master机器
scp /root/.ssh/authorized_keys root@slave1:/root/.ssh/
scp /root/.ssh/authorized_keys root@slave2:/root/.ssh/
# slave1机器
scp /root/.ssh/authorized_keys root@master:/root/.ssh/
scp /root/.ssh/authorized_keys root@slave2:/root/.ssh/关闭每台机器的防火墙
# 关闭防火墙
systemctl stop firewalld.service
# 禁止防火墙开机自启
systemctl disable firewalld.service
# 查看防火墙状态
firewall-cmd --state配置 ZooKeeper
解压 ZooKeeper 并 配置环境变量
[root@master zookeeper]# tar -zxvf zookeeper-3.4.5.tar.gz
[root@master zookeeper]# pwd
/usr/local/src/zookeeper
# 追加到环境变量
[root@master zookeeper]# vi ~/.bash_profile
# zookeeper
export ZK_HOME=/usr/local/src/zookeeper/zookeeper-3.4.5
export PATH=$PATH:$ZK_HOME/bin:
[root@master zookeeper]# source ~/.bash_profile配置 ZooKeeper 集群
进入到 ZooKeeper 的 conf/ 目录下
# 拷贝 zoo_sample.cfg 并重命名为 zoo.cfg
[root@master conf]# cp zoo_sample.cfg zoo.cfg修改 zoo.cfg 文件
# 第一处修改 如没有也可以自己加上 这个路径需要自己创建好
# example sakes.
dataDir=/usr/local/src/zookeeper/DataZk
# 在最后添加,指定myid集群主机及端口,机器数必须为奇数
server.1=192.168.176.61:2888:3888
server.2=192.168.176.62:2888:3888
server.3=192.168.176.63:2888:3888进入 DataZk 目录
添加 Zookeeper 用于识别当前机器的 ID
[root@master DataZk]# echo 1 > myid
[root@master DataZk]# cat myid
1
# myid文件中为 1 ,即表示当前机器为在 zoo.cfg 中指定的 server.1分发配置到其他机器
在 /usr/local/src 目录下执行
[root@master src]# pwd
/usr/local/src
[root@master src]scp -r zookeeper/ root@slave1:/usr/local/src/
[root@master src]scp -r zookeeper/ root@slave2:/usr/local/src/修改其他机器的myid文件
# 在 slave1 上
root@slave1 src]# echo 2 > /usr/local/src/zookeeper/DataZk/myid
# 在 slave2 上
root@slave2 src]# echo 3 > /usr/local/src/zookeeper/DataZk/myid启动 Zookeeper 集群
在 Zookeeper 的 bin/ 目录下启动
# 分别在 master、slave1、slave2 执行 ./zkServer.sh start
[root@master bin]# ./zkServer.sh start
JMX enabled by default
Using config: /usr/local/src/zookeeper/zookeeper-3.4.5/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED查看状态 只有其中一个是 leader ,其他的都是 follower
注意: leader 需要在其中的一个有 namenode 进程的机器上。
# master 查看状态
[root@master bin]# ./zkServer.sh status
JMX enabled by default
Using config: /usr/local/src/zookeeper/zookeeper-3.4.5/bin/../conf/zoo.cfg
Mode: leader
# slave1 查看状态
[root@slave1 bin]# ./zkServer.sh status
JMX enabled by default
Using config: /usr/local/src/zookeeper/zookeeper-3.4.5/bin/../conf/zoo.cfg
Mode: follower
# slave2 查看状态
[root@slave2 bin]# zkServer.sh status
JMX enabled by default
Using config: /usr/local/src/zookeeper/zookeeper-3.4.5/bin/../conf/zoo.cfg
Mode: follower修改 Hadoop 配置文件
在 Hadoop 的 etc/hadoop 目录下
修改 core-site.xml 文件
<!-- hdfs地址,ha模式中是连接到nameservice -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns</value>
</property>
<!-- 这里的路径默认是NameNode、DataNode、JournalNode等存放数据的公共目录,也可以单独指定 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/src/hadoop/tmp</value>
</property>
<!-- 指定ZooKeeper集群的地址和端口。注意,数量一定是奇数,且不少于三个节点-->
<property>
<name>ha.zookeeper.quorum</name>
<value>master:2181,slave1:2181,slave2:2181</value>
</property>
修改 mapred-site.xml 文件
需要复制一份模板 cp mapred-site.xml.template mapred-site.xml
<property>
<!--指定mapreduce运行在yarn上-->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>修改 hdfs-site.xml 文件
<!--执行hdfs的nameservice为ns,需要与 core-site.xml 中定义的 fs.defaultFS 一致-->
<property>
<name>dfs.nameservices</name>
<value>ns</value>
</property>
<!--ns下有两个namenode,分别是nn1、nn2-->
<property>
<name>dfs.ha.namenodes.ns</name>
<value>nn1,nn2</value>
</property>
<!--nn1的RPC通信地址-->
<property>
<name>dfs.namenode.rpc-address.ns.nn1</name>
<value>master:9000</value>
</property>
<!--nn1的http通信地址-->
<property>
<name>dfs.namenode.http-address.ns.nn1</name>
<value>master:50070</value>
</property>
<!--nn2的RPC通信地址-->
<property>
<name>dfs.namenode.rpc-address.ns.nn2</name>
<value>slave1:9000</value>
</property>
<!--nn2的http通信地址-->
<property>
<name>dfs.namenode.http-address.ns.nn2</name>
<value>slave1:50070</value>
</property>
<!--指定namenode的元数据在JournalNode上的存放位置,这样,namenode2可以从jn集群里获取最新的namenode的信息,达到热备的效果-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://master:8485;slave1:8485;slave2:8485/ns</value>
</property>
<!--指定JournalNode存放数据的位置-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/usr/local/src/hadoop/journal</value>
</property>
<!--开启namenode故障时自动切换-->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!--配置切换的实现方式-->
<property>
<name>dfs.client.failover.proxy.provider.ns</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!--配置隔离机制:通过秘钥隔离机制-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!--配置隔离机制的ssh登录秘钥所在的位置-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!--配置namenode数据存放的位置,可以不配置,如果不配置,默认用的是
core-site.xml里配置的hadoop.tmp.dir的路径-->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///usr/local/src/hadoop/tmp/namenode</value>
</property>
<!--配置datanode数据存放的位置,可以不配置,如果不配置,默认用的是
core-site.xml里配置的hadoop.tmp.dir的路径-->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///usr/local/src/hadoop/tmp/datanode</value>
</property>
<!--配置block副本数量-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--设置hdfs的操作权限,false表示任何用户都可以在hdfs上操作文件-->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>修改 yarn-site.xml 文件
<!--开启YARN HA -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!--指定两个resourcemanager的名称-->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!--配置rm1,rm2的主机-->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>master</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>slave1</value>
</property>
<!--开启yarn恢复机制-->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!--执行rm恢复机制实现类-->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<!--配置zookeeper的地址-->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>master:2181,slave1:2181,slave2:2181</value>
<description>For multiple zk services, separate them with comma</description>
</property>
<!--指定YARN HA的名称-->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yarn-ha</value>
</property>
<property>
<!--指定yarn的老大resoucemanager的地址-->
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<!--NodeManager获取数据的方式-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>修改 slaves 文件
指定 datanode 节点
[root@master hadoop]# cat slaves
master
slave1
slave2配置Hadoop 和 ZooKeeper环境
为了方便执行命令,配置过就不用配置了
[root@master /]# vi ~/.bash_profile
# 追加到后面
# hadoop
export HADOOP_HOME=/usr/local/src/hadoop/hadoop-2.6.0
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:
# zookeeper
export ZK_HOME=/usr/local/src/zookeeper/zookeeper-3.4.5
export PATH=$PATH:$ZK_HOME/bin:
[root@master /]# source ~/.bash_profile分发配置
在 /usr/local/src 目录下执行
# 分发 Hadoop 文件
scp -r hadoop/ root@slave1:/usr/local/src/
scp -r hadoop/ root@slave2:/usr/local/src/
# 分发环境变量
scp ~/.bash_profile root@slave1:~/
scp ~/.bash_profile root@slave2:~/启动 Zookeeper 集群
启动结果是 leader 需要在其中一个 namenode 上,如果不是,请杀死每台机器的 QuorumPeerMain 进程,重新启动
# 每台机器执行
# 启动命令
zkServer.sh start
# 查询状态命令
zkServer.sh status格式化 Zookeeper 的 leader 节点
hdfs zkfc -formatZK启动 Hadoop 集群
两个NameNode为了数据同步,会通过一组称作JournalNodes的独立进程进行相互通信。当active状态的NameNode的命名空间有任何修改时,会告知大部分的JournalNodes进程。standby状态的NameNode有能力读取JNs中的变更信息,并且一直监控edit log的变化,把变化应用于自己的命名空间。standby可以确保在集群出错时,命名空间状态已经完全同步了。
启动 journalNode集群,用于主备节点的信息同步
在每台机器上都上输入
hadoop-daemon.sh start journalnode 格式化 Zookeeper 的 leader 上的 namenode 进程
在准备的 namenode 上还有 leader 的机器执行
hdfs namenode -format启动有 leader 的 namenode 进程作为 活跃(active)
在有 namenode 还有 leader 的机器执行
hadoop-daemon.sh start namenode设置另一个 namenode 作为 备用(standby)
在准备的另一个 namenode 上执行
hdfs namenode -bootstrapStandby启动 备用(standby) 的 namenode 进程
备用(standby)上执行
hadoop-daemon.sh start namenode启动所有的 datanode 进程
在活跃(active)机器上执行
hadoop-daemons.sh start datanode启动 zkfc 用于检测 namenode 的监控状态 和 选举
在有 namenode 的机器上执行
hadoop-daemon.sh start zkfc启动 yarn 资源管理
在 leader 上执行
start-yarn.sh下载主备切换依赖
主备机器都要下载
yum install psmisc查看各个机器的进程
| 活跃机器 | 备用机器 | 其他 |
|---|---|---|
| Jps | Jps | Jps |
| DataNode | DataNode | DataNode |
| JournalNode | JournalNode | JournalNode |
| QuorumPeerMain | QuorumPeerMain | QuorumPeerMain |
| NodeManager | NodeManager | NodeManager |
| ResourceManager | ResourceManager | |
| DFSZKFailoverController | DFSZKFailoverController | |
| NameNode | NameNode |
Hadoop 高可用测试
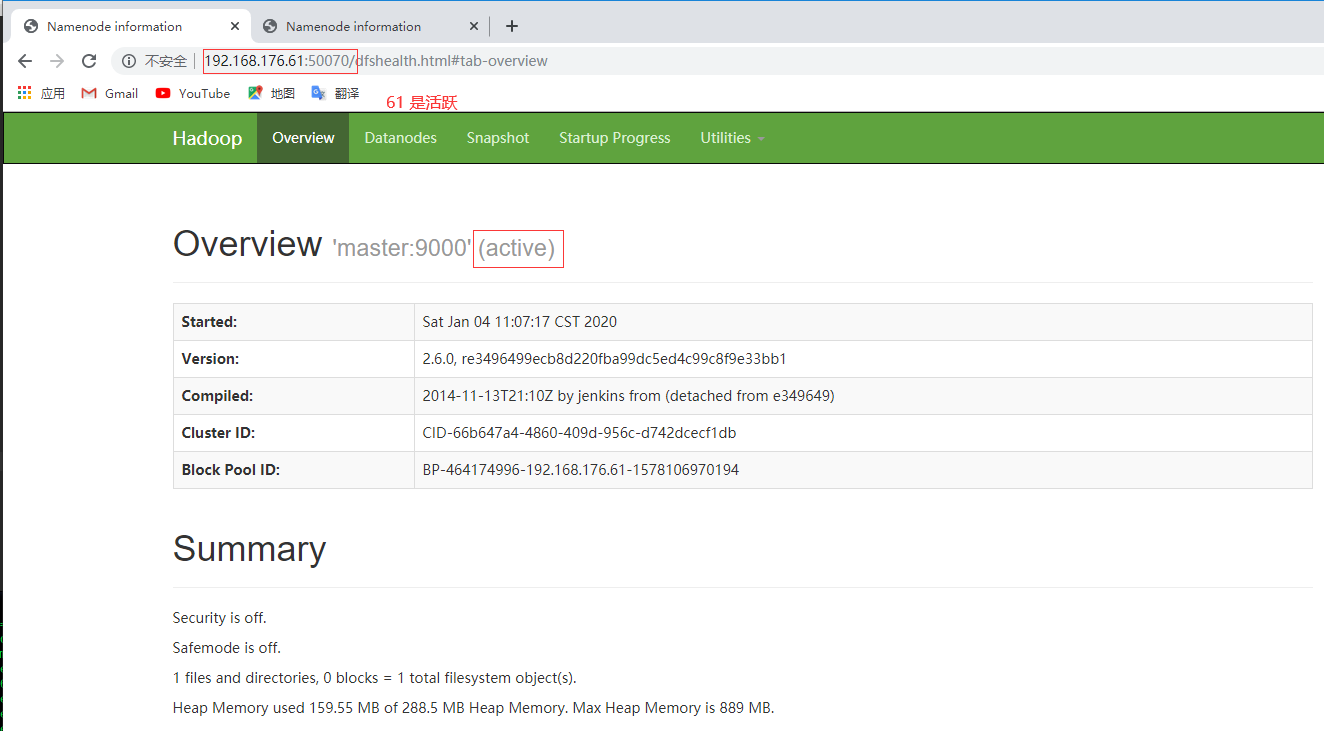
查看活跃机器
[]()
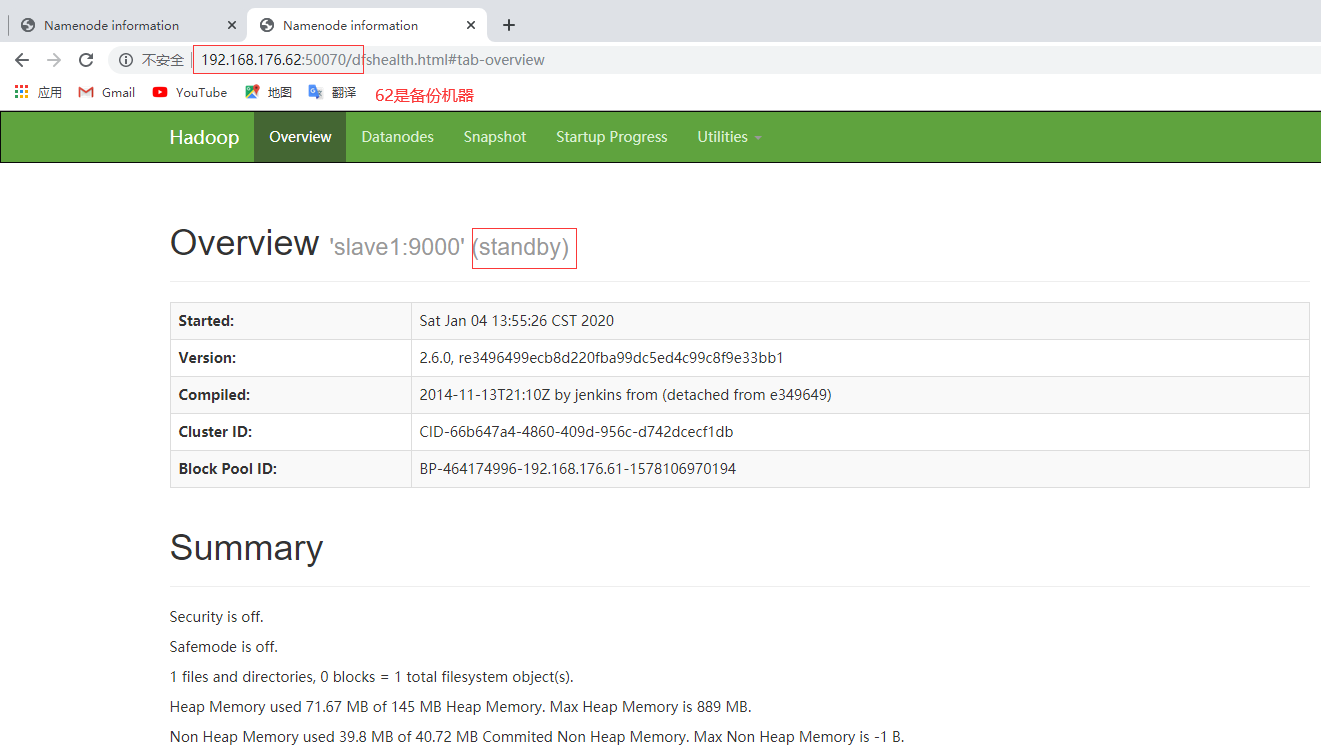
查看备份机器
[]()
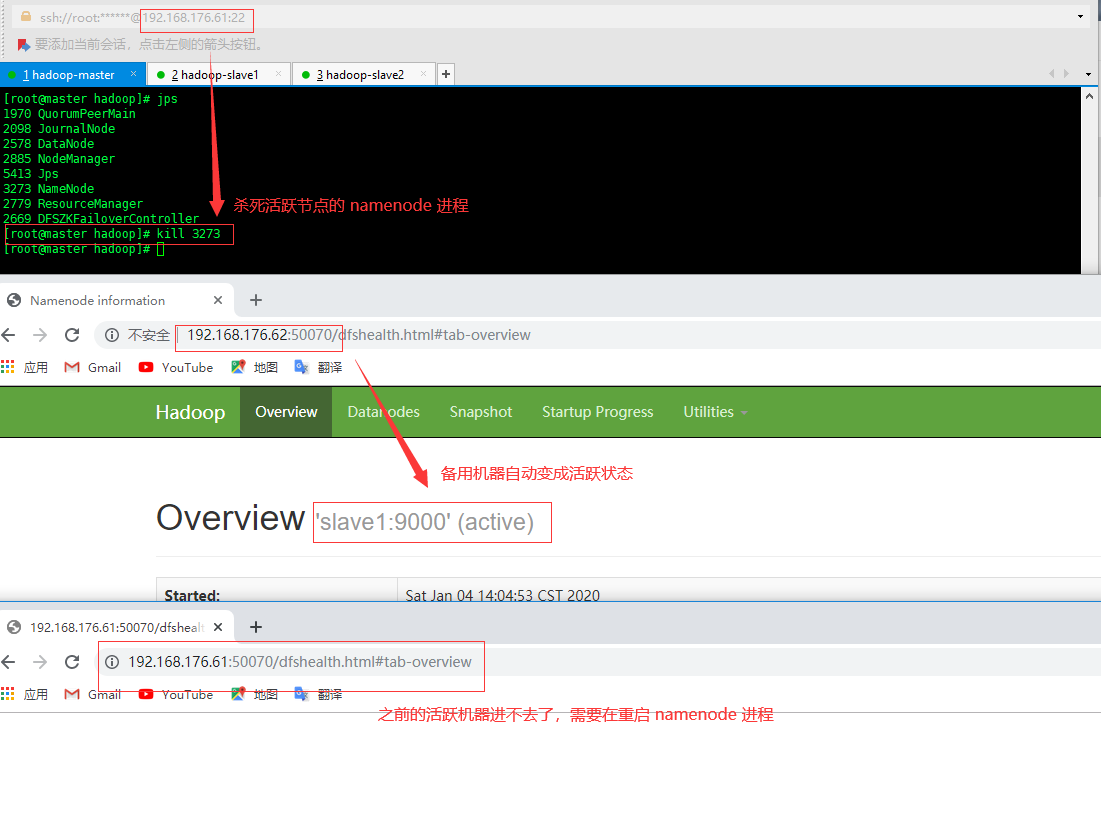
现在杀死活跃机器的 namenode 进程,再查看备份机器的状态,发现主备切换了
[]()
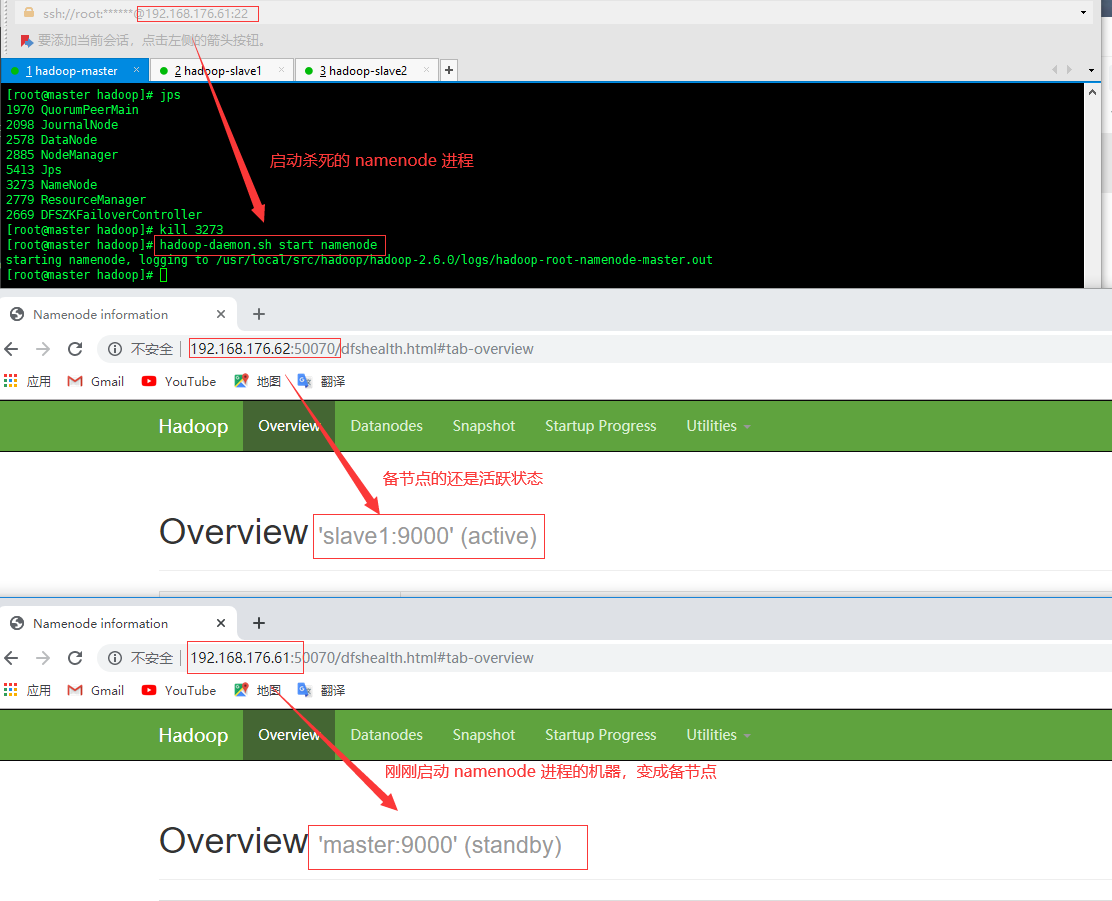
启动杀死 namenode 进程的机器,再查看两机器状态
hadoop-daemon.sh start namenode[]()
安装好后,启动 Hadoop HA集群
首先启动 Zookeeper 的集群查看选举
每台机器执行
# 启动命令
zkServer.sh start
# 查询状态命令
zkServer.sh status
# 结果也是要选择一个 leader 在一个 namenode 上,不然杀死 QuorumPeerMain 进程,重新选举在一个 namenode 不是 leader 上启动全部进程
[root@master ~]# start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [master slave1]
slave1: starting namenode, logging to /usr/local/src/hadoop/hadoop-2.6.0/logs/hadoop-root-namenode-slave1.out
master: starting namenode, logging to /usr/local/src/hadoop/hadoop-2.6.0/logs/hadoop-root-namenode-master.out
slave1: starting datanode, logging to /usr/local/src/hadoop/hadoop-2.6.0/logs/hadoop-root-datanode-slave1.out
slave2: starting datanode, logging to /usr/local/src/hadoop/hadoop-2.6.0/logs/hadoop-root-datanode-slave2.out
master: starting datanode, logging to /usr/local/src/hadoop/hadoop-2.6.0/logs/hadoop-root-datanode-master.out
Starting journal nodes [master slave1 slave2]
slave1: starting journalnode, logging to /usr/local/src/hadoop/hadoop-2.6.0/logs/hadoop-root-journalnode-slave1.out
master: starting journalnode, logging to /usr/local/src/hadoop/hadoop-2.6.0/logs/hadoop-root-journalnode-master.out
slave2: starting journalnode, logging to /usr/local/src/hadoop/hadoop-2.6.0/logs/hadoop-root-journalnode-slave2.out
Starting ZK Failover Controllers on NN hosts [master slave1]
slave1: starting zkfc, logging to /usr/local/src/hadoop/hadoop-2.6.0/logs/hadoop-root-zkfc-slave1.out
master: starting zkfc, logging to /usr/local/src/hadoop/hadoop-2.6.0/logs/hadoop-root-zkfc-master.out
starting yarn daemons
starting resourcemanager, logging to /usr/local/src/hadoop/hadoop-2.6.0/logs/yarn-root-resourcemanager-master.out
slave1: starting nodemanager, logging to /usr/local/src/hadoop/hadoop-2.6.0/logs/yarn-root-nodemanager-slave1.out
slave2: starting nodemanager, logging to /usr/local/src/hadoop/hadoop-2.6.0/logs/yarn-root-nodemanager-slave2.out
master: starting nodemanager, logging to /usr/local/src/hadoop/hadoop-2.6.0/logs/yarn-root-nodemanager-master.out
{{nature('2020-01-02 16:47:07')}} {{format('12641')}}人已阅读
{{nature('2019-12-11 20:43:10')}} {{format('9527')}}人已阅读
{{nature('2019-12-26 17:20:52')}} {{format('7573')}}人已阅读
{{nature('2019-12-26 16:03:55')}} {{format('5017')}}人已阅读
目录
标签云
一言
评论 0
{{userInfo.data?.nickname}}
{{userInfo.data?.email}}